Um teste de hipótese é uma técnica estatística cujo intuito é verificar se uma dada amostra de dados é, ou não, compatível com uma hipótese feita sobre a população que lhe deu origem. Um teste de hipóteses coloca lado-a-lado duas hipóteses sobre a população que deu origem à amostra de dados que temos à disposição - uma hipótese inicial, ou hipótese nula, e uma hipótese alternativa, normalmente designadas por H0 e H1 respetivamente e referem-se a uma caraterística de uma população. O objetivo do teste de hipótese é fornecer ferramentas que nos permitam validar ou rejeitar uma hipótese através dos resultados da amostra.
Definindo hipóteses
Hipótese de Nulidade (H0): é a hipótese a ser testada. Se testarmos, por exemplo, as igualdades entre duas médias, podem ter: H0: media1 (igual a) media2.
Hipótese Alternativa (Ha): é a hipótese que contraria H0. Para o caso das duas médias anteriores poderemos ter: Ha1: media1 (diferente da) media 2, Ha2: media1 < media2 e Ha3: media1 > media2.
P-valor
O p-valor é a probabilidade de observar o resultado encontrado (diferença) tão grande ou ainda maior (favorável a hipótese alternativa) considerando a hipotese nula como verdadeira. Em outras palavras, o p-valor (ou valor de probabilidade) indica a probabilidade de obter um resultado igual ou mais extremo do que o observado, assumindo-se que a hipótese nula (a hipótese de que não há diferença entre as amostras ou populações em estudo) seja verdadeira. O p-valor é uma medida de evidência contra a hipótese nula – um p-valor pequeno indica que é improvável que o resultado observado tenha ocorrido por acaso, o que sugere que a hipótese nula é falsa. Por outro lado, um p-valor grande indica que é provável que o resultado observado tenha ocorrido por acaso, o que sugere que a hipótese nula é verdadeira. O valor do p-valor é geralmente comparado com um nível de significância pré-determinado (geralmente 0,05 ou 0,01) para decidir se rejeita-se ou não a hipótese nula. Se o p-valor for menor do que o nível de significância, rejeita-se a hipótese nula e conclui-se que há evidência estatística de que há diferença entre as amostras ou populações em estudo. Caso contrário, não se rejeita a hipótese nula e conclui-se que não há evidência estatística de que haja diferença entre as amostras ou populações em estudo.
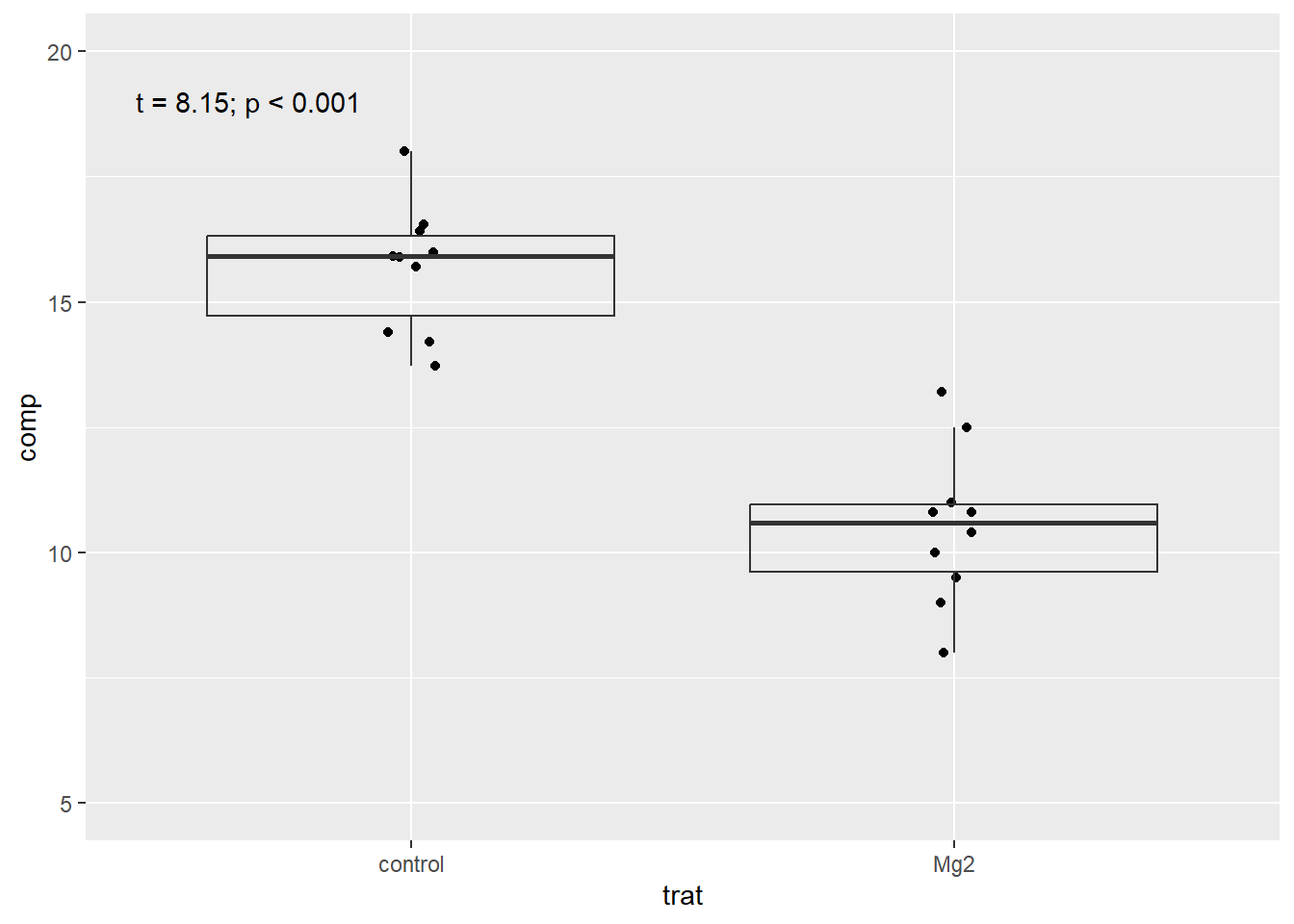
Exportação e visualização dos dados: usando os dados do conjunto magnésio, plotamos um gráfico boxplot. Usamos a função annotate() para escrever anotações dentro do gráfico.
library(tidyverse)library(readxl)mg <-read_excel("dados-diversos.xlsx")mg |>ggplot(aes(trat, comp))+geom_jitter(width =0.05)+geom_boxplot(fill =NA,outlier.colour =NA)+ylim(5, 20)+annotate(geom ="text",x =0.7, y =19,label ="t = 8.15; p < 0.001")
Exemplificando o uso do teste t
Abaixo, criamos um novo objeto (mg2) e atribuímos mg a ele para realizar a função pivot_wider(). Esta função “alarga” os dados, aumentando o número de colunas e diminuindo o número de linhas. Nesta função usa-se names_from e values_from, onde: names_from refere-se a coluna cujos valores serão usados como nomes de coluna e values_from refere-se a coluna cujos valores serão usados como valores de célula.
Função t.test: usa-se a função t test() para calcular o valor de t. Primeiro, realizamos um teste t para comparar as médias dos grupos “Mg2” e “control” no data frame “mg2”. Após isso, o pacote “report” é carregado e a função report() é usada para gerar um relatório formatado dos resultados do teste t.
t <-t.test(mg2$Mg2, mg2$control)library(report)report(t)
Effect sizes were labelled following Cohen's (1988) recommendations.
The Welch Two Sample t-test testing the difference between mg2$Mg2 and
mg2$control (mean of x = 10.52, mean of y = 15.68) suggests that the effect is
negative, statistically significant, and large (difference = -5.16, 95% CI
[-6.49, -3.83], t(17.35) = -8.15, p < .001; Cohen's d = -3.65, 95% CI [-5.12,
-2.14])
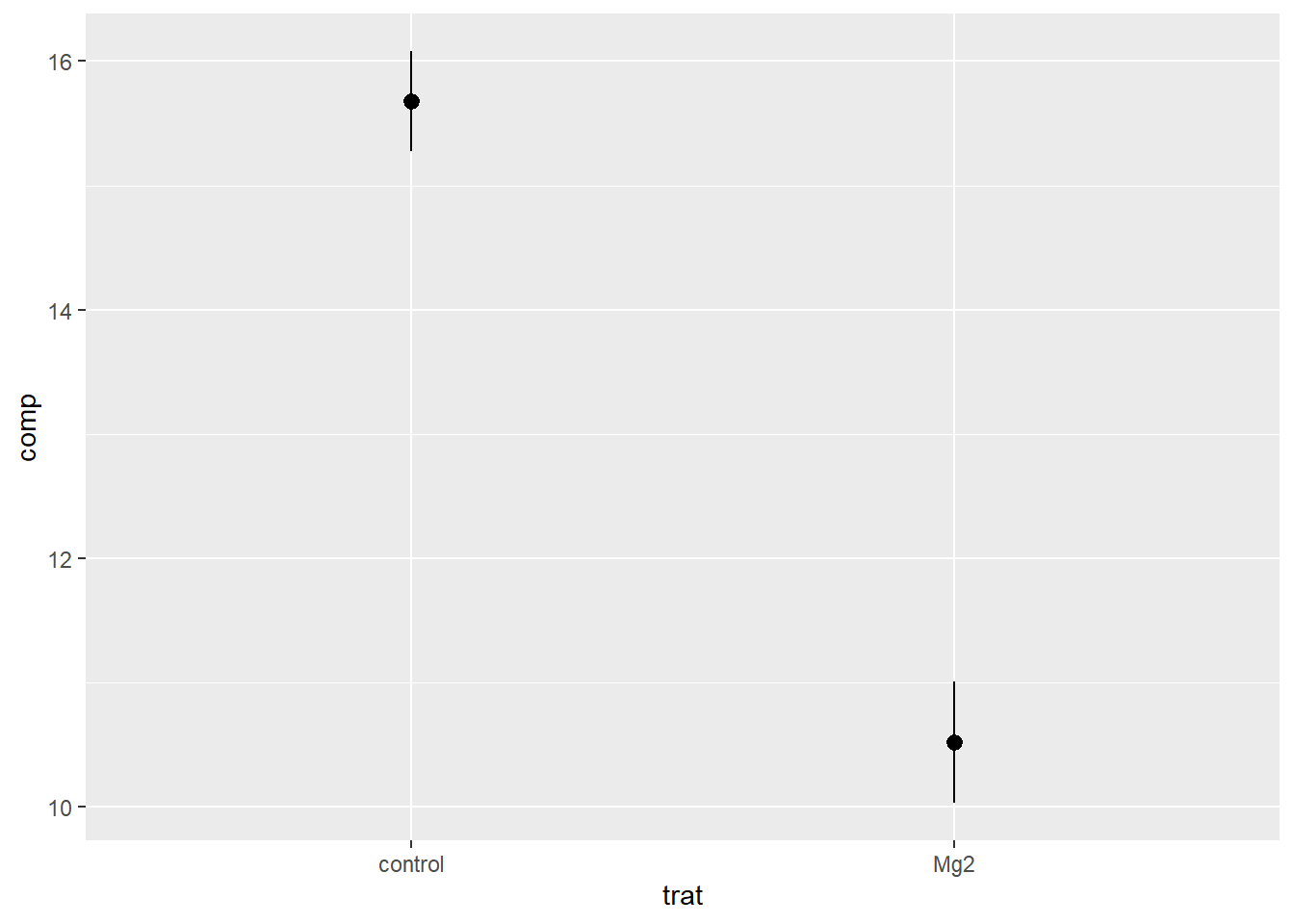
Visualizando o resultado: agora, plotamos um gráfico simples usando o data frame “mg” e as variáveis trat e comp como os eixos x e y. Em seguida, solicitamos um resumo estatístico completo (função stat_summary com fun.data) ao gráfico mostrando as médias e os erros padrão da média para cada nível da variável trat (mean_se).
Fun.data: função de resumo completa - uma função que recebe os dados completos e deve retornar um quadro de dados com variáveis ymin, y e ymax. Deve receber o quadro de dados como entrada e retornar o quadro de dados como saída.
O pacote infer realiza a inferência estatística usando uma linguagem que seja coerente com a estrutura do tidyverse. O pacote é centrado em 4 funções principais para visualizar e extrair valores: specify() - permite especificar a variável, ou relacionamento entre variáveis, em que se está interessado. hypothesize() - permite declarar a hipótese nula. generate() - permite gerar dados que refletem a hipótese nula. calculate() - permite calcular uma distribuição de estatísticas a partir dos dados gerados para formar a distribuição nula.
library(infer) mg |>t_test(comp ~ trat, order =c("control", "Mg2"))
Acima, pedimos que o pacote infer fosse carregado e, em seguida, realizamos um teste t usando a função t_test() para comparar as médias dos grupos definidos pela variável “trat” no data frame “mg2”. A ordem dos níveis da variável “trat” é especificada para garantir que a comparação seja feita corretamente.