library(tidyverse)
library(readxl)
fungicida_campo <- read_excel("dados-diversos.xlsx",
"fungicida_campo")Gráficos 2
Gráficos de dispersão, histograma e gráfico de densidade
Scatterplots
Um Scatterplot exibe a relação entre 2 variáveis numéricas, ajudando a identificar padrões ou correlações entre elas, cada ponto representa uma observação. Os gráficos de dispersão são frequentemente usados para representar dados que possuem duas variáveis contínuas, como comprimento e largura, tempo e velocidade, ou temperatura e umidade. A sua posição no eixo X (horizontal) e Y (vertical) representa os valores das 2 variáveis (primeiro aplica a variável x e depois a y). Usando ggplot2, os gráficos de dispersão são construídos usando a função geom_point. A função geom_point() compreende a seguinte estética:
alpha: trabalha com a transparência dos pontos (pontos ficam mais transparentes e ajuda caso haja sobreposição);
colour: usada adicionar cor usa-se a (função color = nome da cor);
fill: define a cor. O nome da cor, por ser texto, deve ser escrita entre aspas;
shape: utilizada para adicionar diferentes formas ou tipos de marcadores para diferenciar as variáveis (ex. quadrado e triângulo);
Size: define o tamanho do box, retorna um vetor numérico de comprimento length(x ).
Importação dos dados: Para atribuir os dados de uma aba especifica do excel, usa-se o nome da aba e após isso a função read_excel seguido do nome do arquivo excel entre aspas (endereço) e logo após insere a vírgula e o nome da aba dos dados (também pode ser usado o número da aba de dados). O data frame deve ter o mesmo nome da aba quando for ser atribuido.
Visualização: Depois, plota-se os dados definindo-se o eixo x e depois o eixo y. Usa-se o stat_summary para plotar a média de forma simples.
fungicida_campo |>
ggplot(aes(trat, sev))+
geom_jitter(width = 0.1,
color = "gray60")+
stat_summary(fun = mean,
color = "red")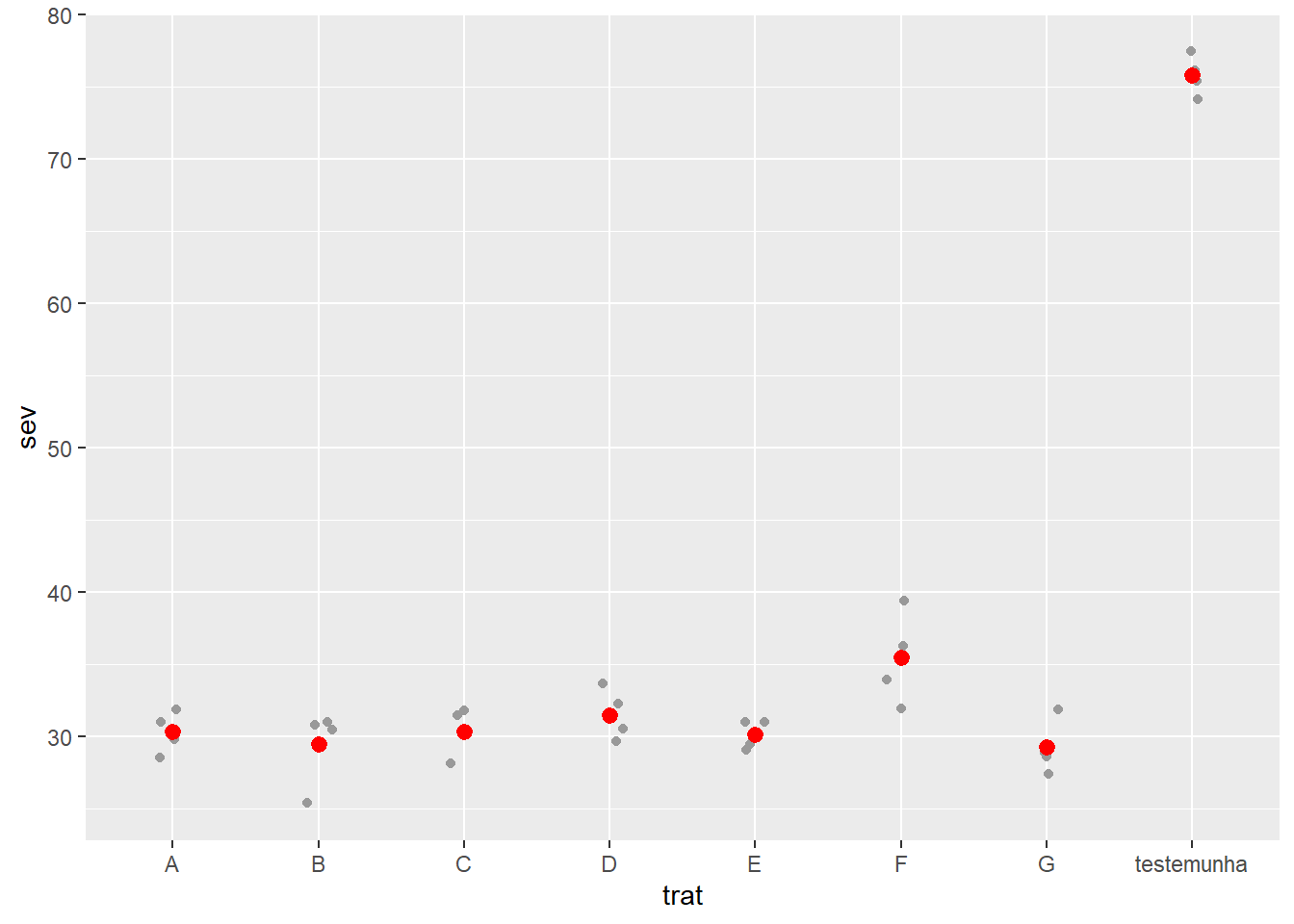
Para plotar a média de forma rápida e não precisar do by_summurise = mean_se.
fungicida_campo |>
ggplot(aes(trat, sev))+
geom_jitter(width = 0.1,
color = "gray60")+
stat_summary(fun.data = mean_se,
color = "red")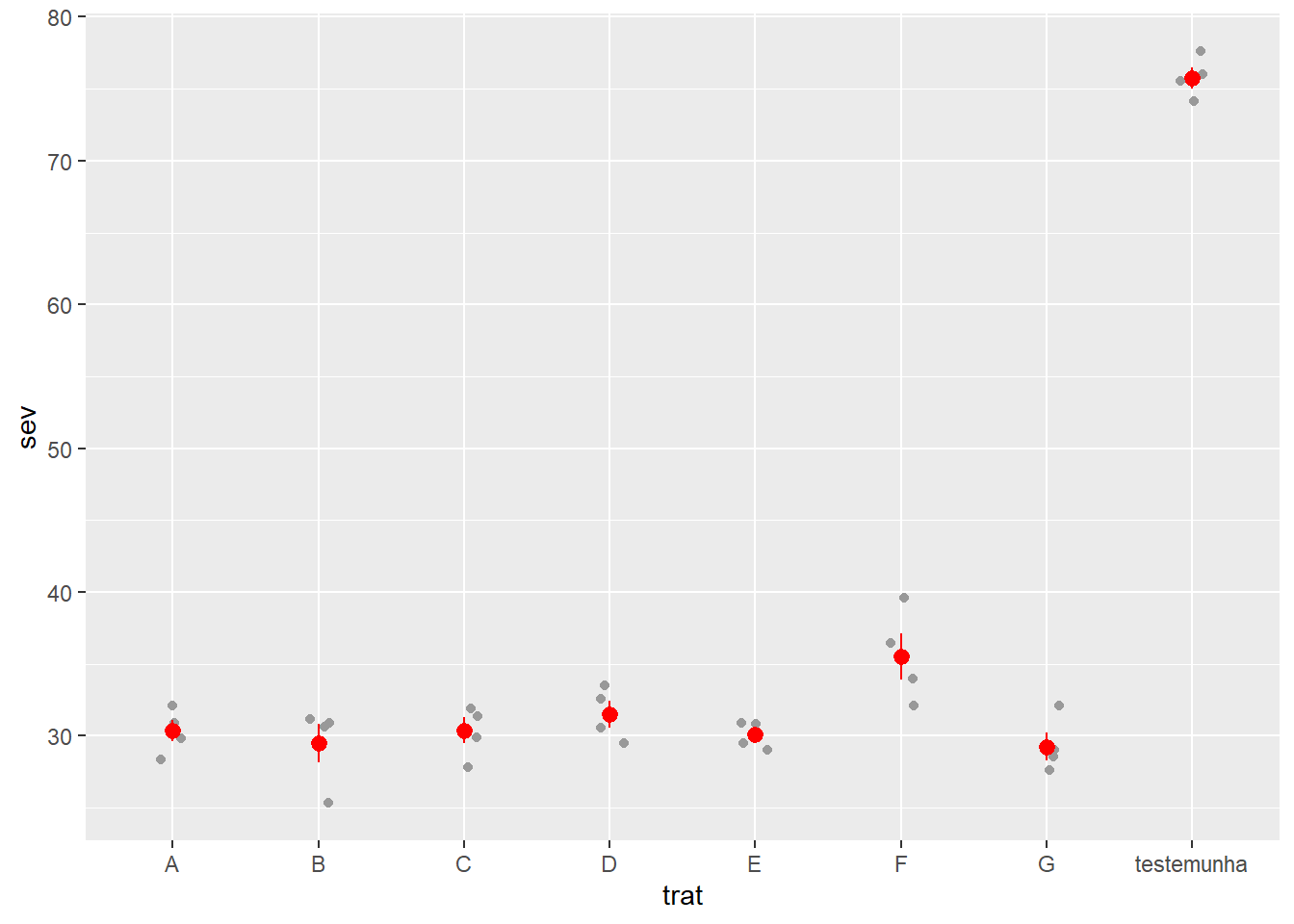
Mudando o eixo x para yld, um das variáveis do banco de dados fungicida_campo. Se inserir a função alpha dentro da função geom_point, os pontos ficam mais transparentes.
library(ggthemes)
fungicida_campo |>
ggplot(aes(sev, yld,
color = trat))+
geom_point(size = 3)+
scale_color_colorblind()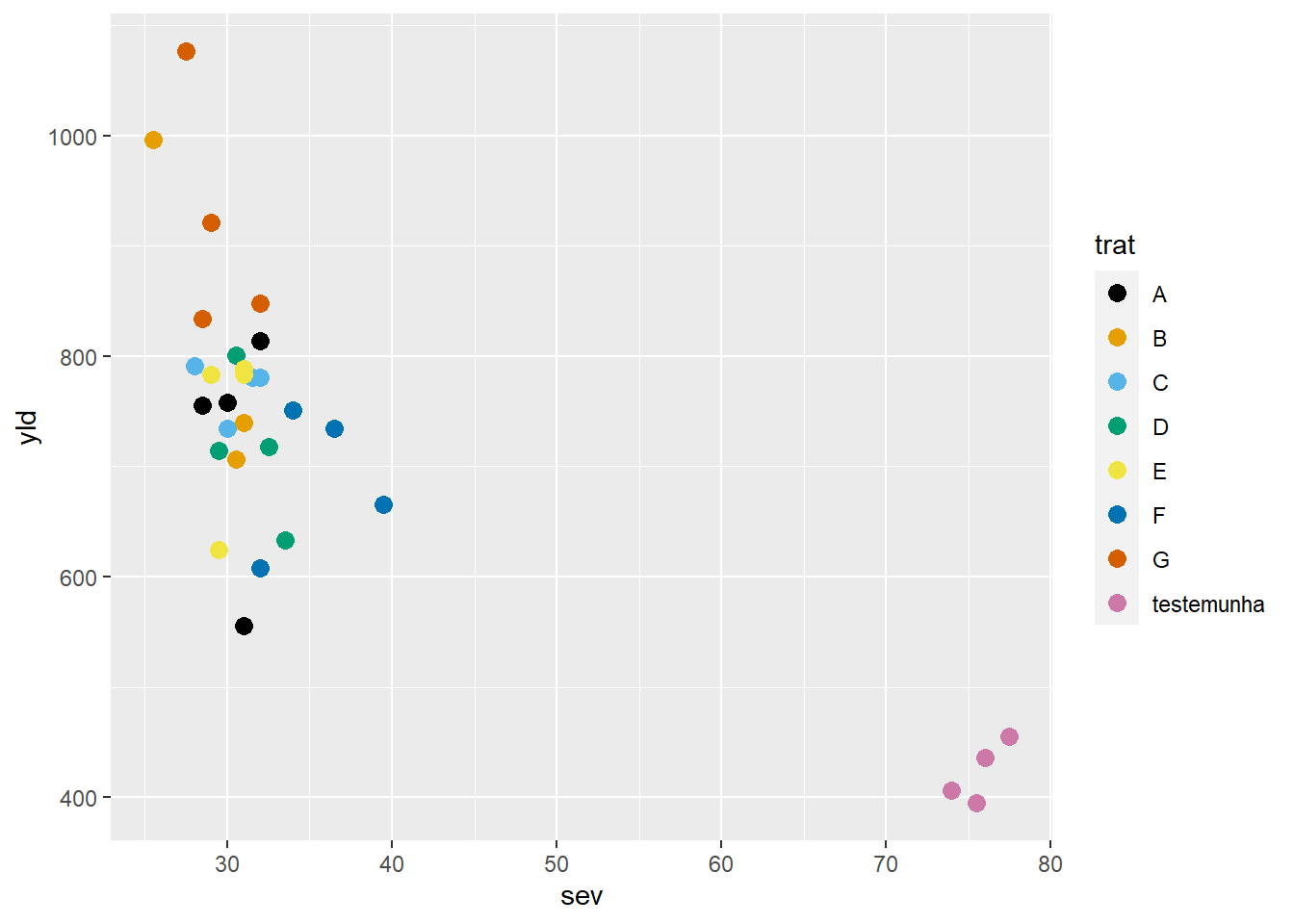
Linha de tendência: para criar uma linha de tendência, usa-se a função geom_smooth. Para retirar o erro, usa-se a função se = FALSE e linetype. Method lm ajusta os dados a função linear.
fungicida_campo |>
ggplot(aes(sev, yld))+
geom_point(size = 3)+
scale_color_colorblind()+
geom_smooth(method = "lm",
se = FALSE,
color = "black",
linetype = "solid",
size = 2)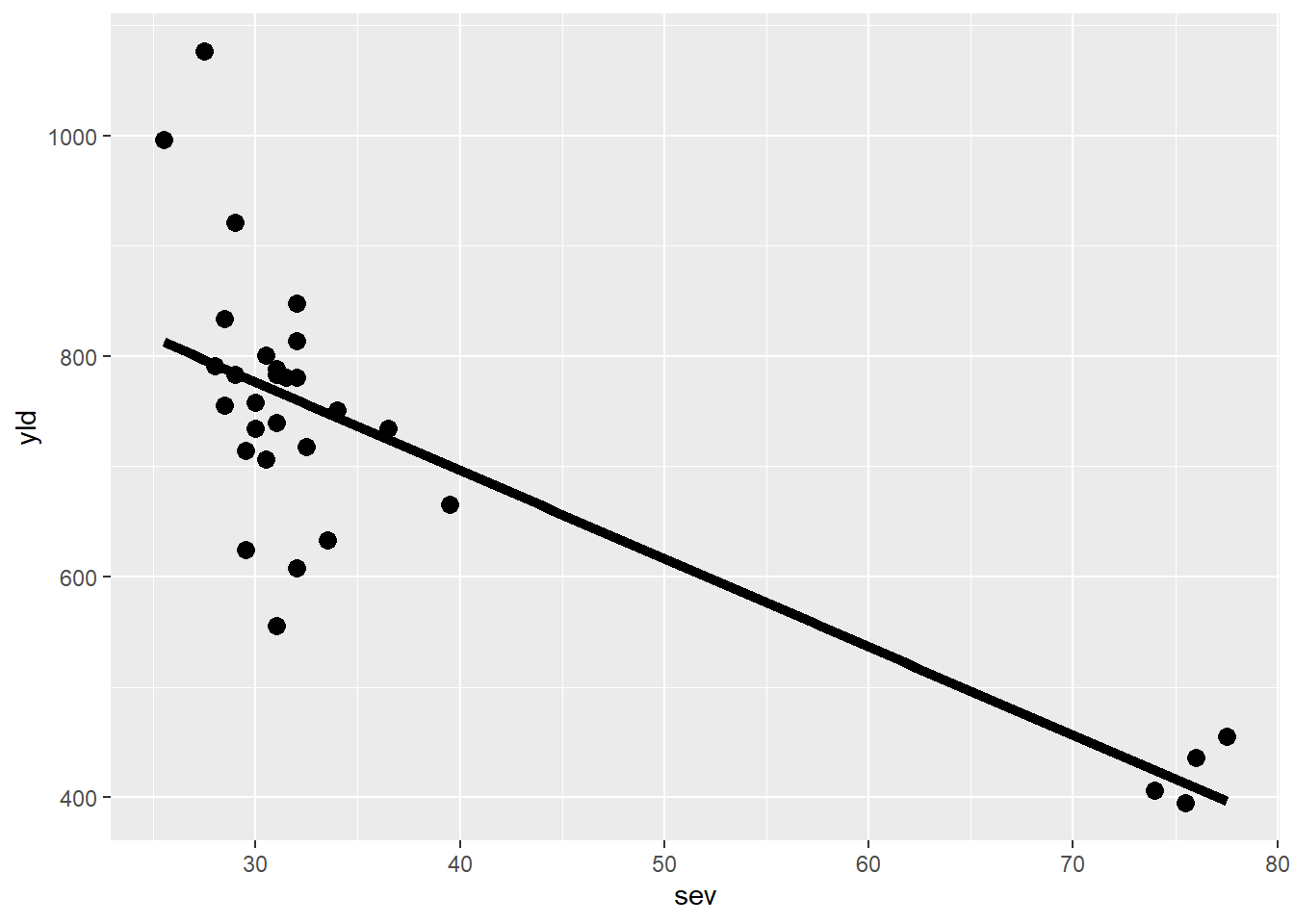
Gráficos de dispersão para análise fatorial
Mudando o subconjunto de dados para milho: Ver a variação da produtividade dos hibridos de milho em função dos métodos de inoculação.
milho <- read_excel("dados-diversos.xlsx", "milho")
milho |>
ggplot(aes(hybrid, yield, color = method))+
geom_jitter(size = 2)+
facet_wrap(~hybrid)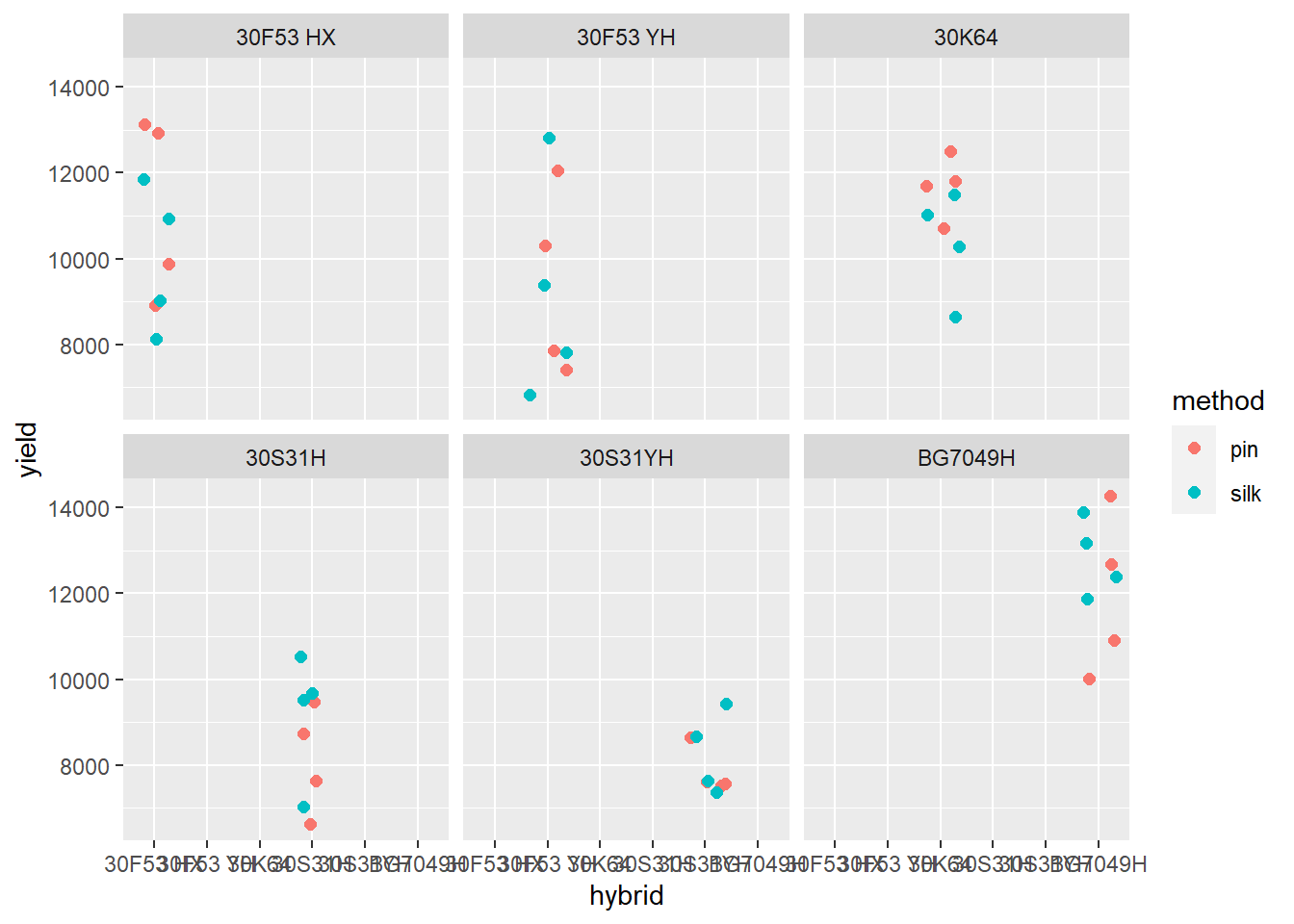
#ou, para ver qual hibrido dá mais doença:
milho |>
ggplot(aes(method, index, color = method))+
geom_jitter(size = 2)+
facet_wrap(~hybrid)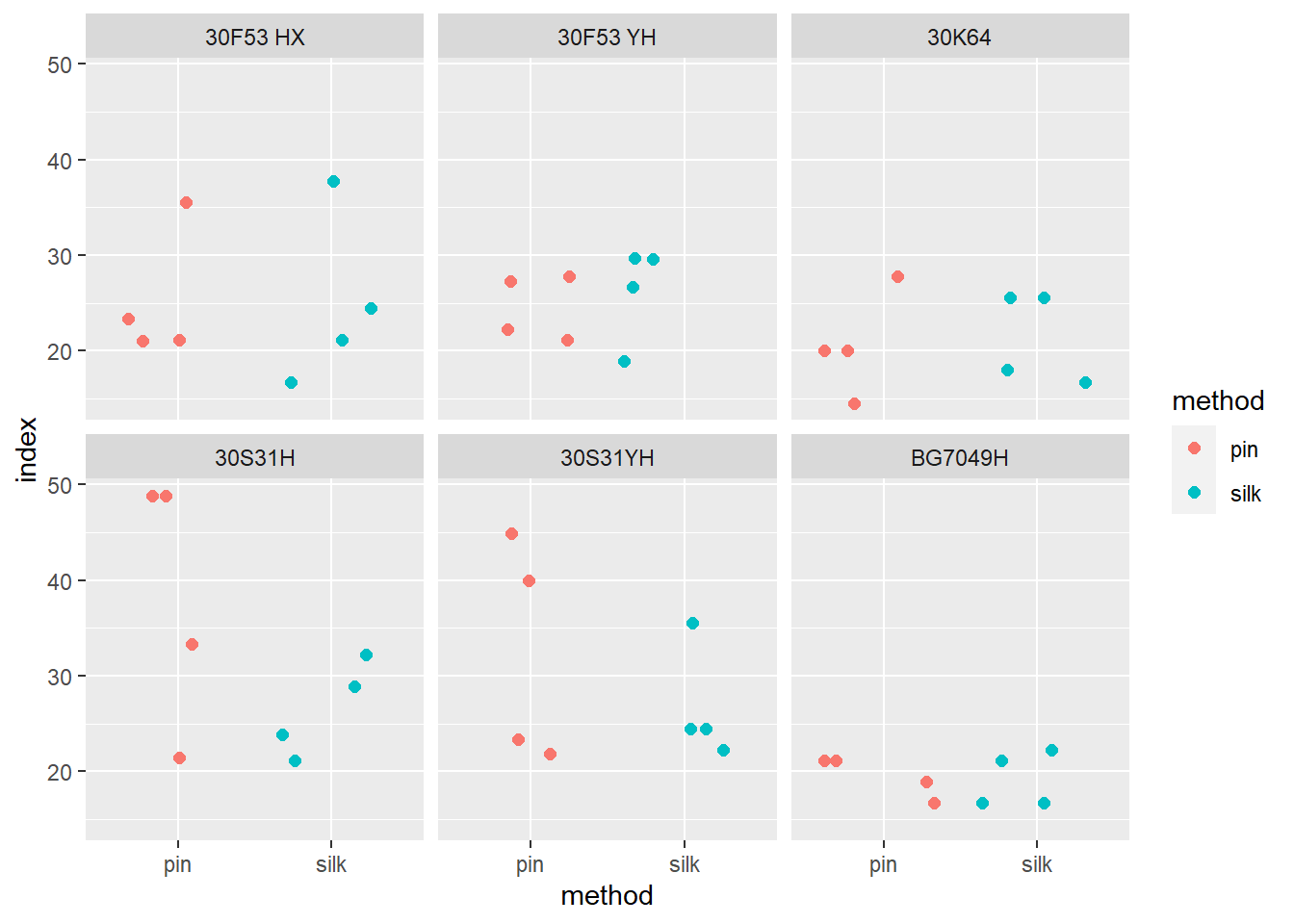
Histogramas
Para construir histogramas, usamos o geom_histogram. Esse geom só precisa do atributo x (o eixo y é construído automaticamente). Histogramas são úteis para avaliarmos a distribuição de uma variável. São frequentemente usados para representar dados contínuos, como medidas físicas, tempo, idade ou outras variáveis que podem ser divididas em intervalos. Os histogramas ajudam a visualizar a forma da distribuição de dados contínuos, incluindo informações sobre tendência central, variabilidade e assimetria. A função geom_histogram() suporta as seguintes estéticas:
Bins = refere-se ao número de barras presente no gráfico.
Color = função usada para mudar a cor da linha do bloco.
Fill = função para mudar a cor dos blocos.
Agora, montaremos um histograma brabalhando com 1 variável continua (produtividade). No histograma, tem-se os valores organizados em classe. Qual o padrão de distribuição dos pontos?
p_yield <- milho |>
ggplot(aes(x = yield))+
geom_histogram(bins = 10, color = "black", fill = "green")Mudando de yield para index:
p_index <- milho |>
ggplot(aes(x = index))+
geom_histogram(bins = 10, color = "black", fill = "blue")Combinando gráficos com patchowork: deve-se primeiro definir um nome para cada gráfico
library(patchwork)
(p_yield + p_index)+
plot_annotation(tag_levels = "A")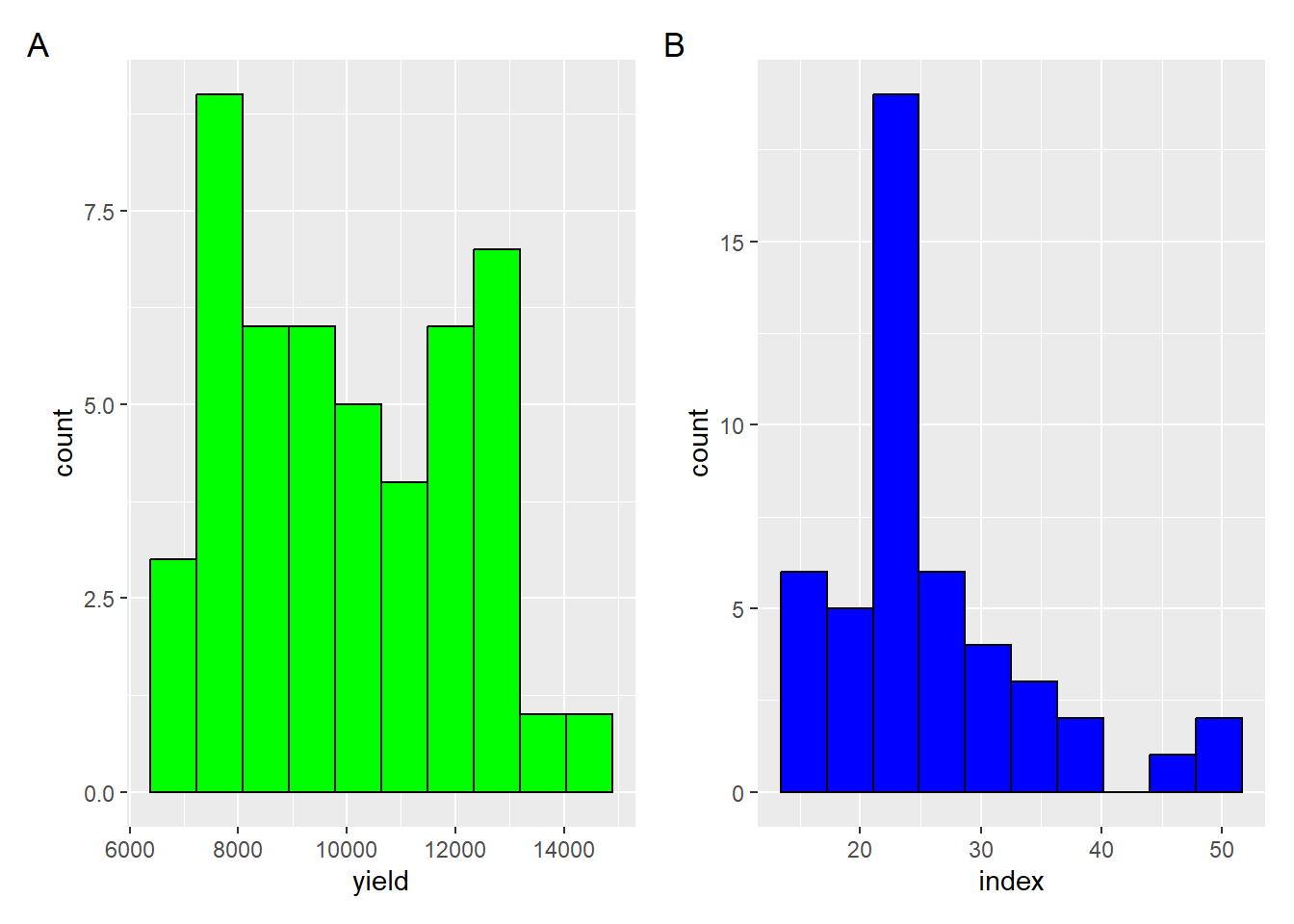
ggsave("figs/histograms.png", bg = "white")Gráfico de densidade
Gráficos de densidade podem ajudar a identificar padrões, tendências, assimetrias e são geralmente usados para representar a distribuição de probabilidade de uma variável contínua (ex.:distribuição de alturas ou pesos de uma população, distribuição de pontuações em um teste padronizado). Para esse tipo de gráfico, a função a ser utilizada é geom_density().
milho |>
ggplot(aes(x = index))+
geom_density()
Gráfico de colunas
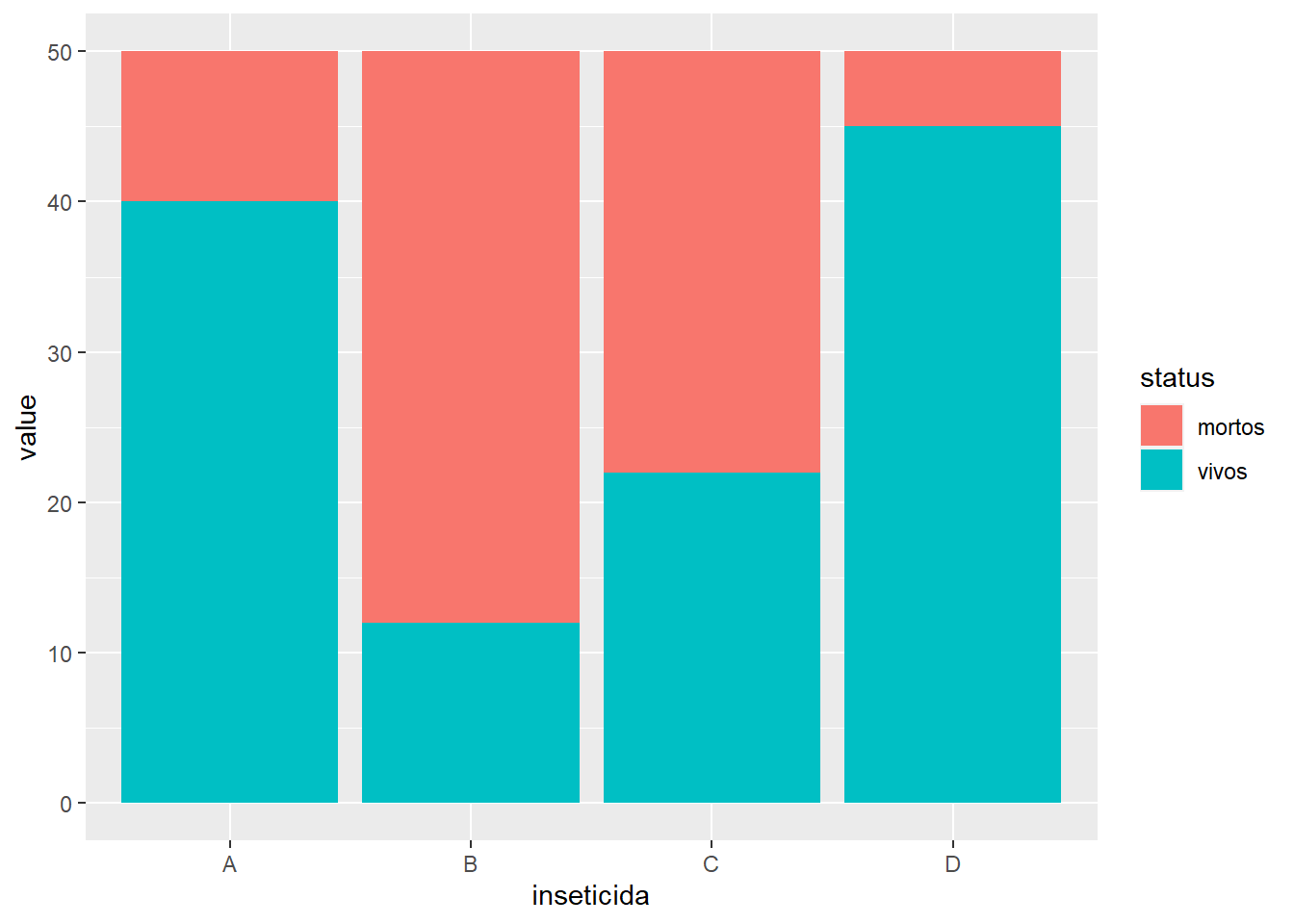
Testando um novo subconjunto de dados: criou-se um gráfico de colunas, onde, no x tem-se inseticida e y é o status. Alterado de formato largo para longo.
insect <- read_excel("dados-diversos.xlsx", "mortalidade")
insect |>
pivot_longer(2:3,
names_to = "status",
values_to = "value") |>
ggplot(aes(inseticida, value, fill = status))+
geom_col()